本文共 7716 字,大约阅读时间需要 25 分钟。
1. 函数
- 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
- 函数能提高应用的模块性,和代码的重复利用率。
- 定义函数的规则: 1). 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。 2). 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。 3). 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。 4). 函数内容以冒号起始,并且缩进。 5). return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
- 语法: Python 定义函数使用 def 关键字,一般格式如下:
def 函数名(参数列表): 函数体
默认情况下,参数值和参数名称是按函数声明中定义的的顺序匹配起来的。
示例:
# 计算面积函数def area(width, height): return width * height passw = 4h = 5print ("width = ", w, " height = ", h, " area = ", area(w,h)) 打印结果:

2. 可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
3. 参数
- 必需参数 必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样
- 关键字参数 关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
- 默认参数 调用函数时,如果没有传递参数,则会使用默认参数。
- 不定长参数 基本语法如下:
def functionname([formal_args,] *var_args_tuple ): "函数_文档字符串" function_suite return [expression]
加了星号(*)的变量名会存放所有未命名的变量参数。如果在函数调用时没有指定参数,它就是一个空元组。
示例:
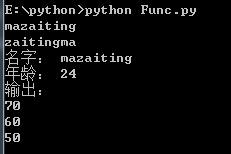
# 必需参数def printStr(str): print(str) passprint("mazaiting")# 关键字参数def printMe(str): print(str) passprintMe(str = "zaitingma")# 默认参数def printInfo(name, age = 24): print("名字:", name) print("年龄:", age) passprintInfo(name = "mazaiting")# 不定长参数def printInfo(arg, *vartuple): print("输出:") print(arg) for var in vartuple: print(var) pass passprintInfo(70, 60, 50) 打印结果:
4. 匿名函数
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
1). lambda 只是一个表达式,函数体比 def 简单很多。 2). lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。 3). lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。 4). 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。语法
lambda 函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
示例:
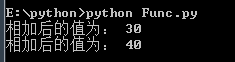
# lambda表达式# 可写函数说明sum = lambda arg1, arg2: arg1 + arg2# 调用sum函数print("相加后的值为:", sum(10, 20))print("相加后的值为:", sum(20, 20)) 打印结果:
5. return语句
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None
示例:# return 语句def sum(arg1, arg2): total = arg1 + arg2 return total pass# 调用sum函数total = sum(10, 20)print("函数:",total) 打印结果:

6. 变量作用域
Python的作用域一共有4种,分别是:
L (Local) 局部作用域E (Enclosing) 闭包函数外的函数中G (Global) 全局作用域B (Built-in) 内建作用域
示例:
# 内建作用域x = int(2.9)# 全局作用域g_count = 0def outer(): # 闭包函数外的函数中 o_count = 1 def inner(): # 局部作用域 i_count = 2 pass pass
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问.
当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字:- global
num = 1def fun1(): global num # 需要使用 global 关键字声明 print(num) num = 123 print(num)fun1()
- nonlocal关键字
def outer(): num = 10 def inner(): nonlocal num # nonlocal关键字声明 num = 100 print(num) inner() print(num)outer()
7. 模块
Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
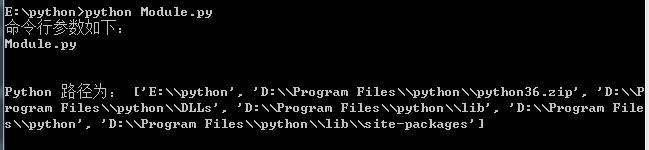
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。 1). 引用标准库 示例:import sysprint("命令行参数如下:")for i in sys.argv: print(i) passprint("\n\nPython 路径为:", sys.path, '\n') 打印结果:
2). import 语句
想使用 Python 源文件,只需在另一个源文件里执行 import 语句,语法如下:import module1[, module2[,... moduleN]
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
示例: Support.py文件:def print_func(str): print("Hello: ", str) return Module.py文件
# 引入Support.py文件# 导入模块import Support# 调用Support中的函数Support.print_func("Mazaiting") 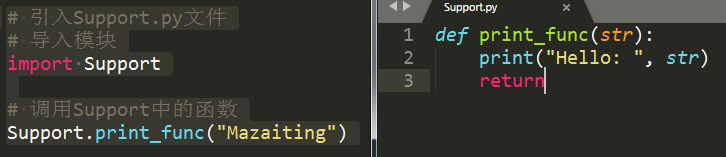
打印结果:

3). From…import* 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
4). name属性
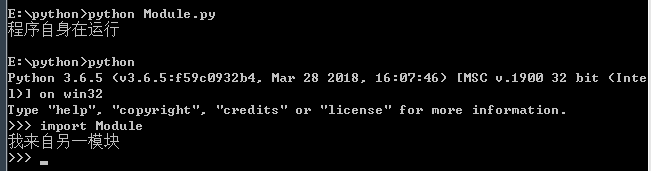
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用name属性来使该程序块仅在该模块自身运行时执行。# Module.pyif __name__ == '__main__': print("程序自身在运行")else: print("我来自另一模块") pass 打印结果:
5). dir() 函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回: 打印结果: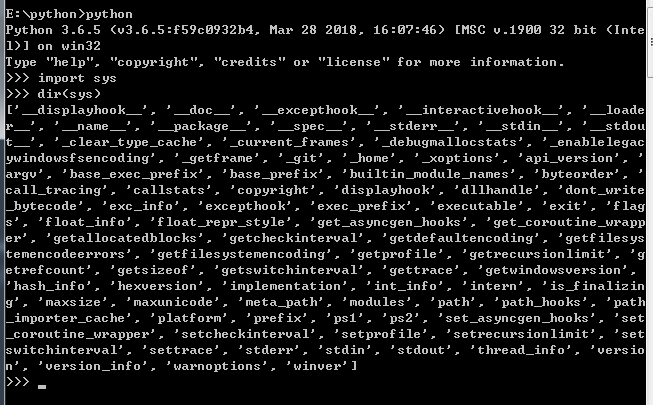
8. 包
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。
比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。 就好像使用模块的时候,你不用担心不同模块之间的全局变量相互影响一样,采用点模块名称这种形式也不用担心不同库之间的模块重名的情况。 这样不同的作者都可以提供 NumPy 模块,或者是 Python 图形库。 不妨假设你想设计一套统一处理声音文件和数据的模块(或者称之为一个"包")。 现存很多种不同的音频文件格式(基本上都是通过后缀名区分的,例如: .wav,:file:.aiff,:file:.au,),所以你需要有一组不断增加的模块,用来在不同的格式之间转换。 并且针对这些音频数据,还有很多不同的操作(比如混音,添加回声,增加均衡器功能,创建人造立体声效果),所以你还需要一组怎么也写不完的模块来处理这些操作。 这里给出了一种可能的包结构(在分层的文件系统中):sound/ 顶层包 __init__.py 初始化 sound 包 formats/ 文件格式转换子包 __init__.py wavread.py wavwrite.py aiffread.py aiffwrite.py auread.py auwrite.py ... effects/ 声音效果子包 __init__.py echo.py surround.py reverse.py ... filters/ filters 子包 __init__.py equalizer.py vocoder.py karaoke.py ...
9. 输入输出
1). 输出
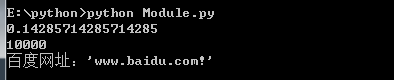
Python两种输出值的方式: 表达式语句和 print() 函数。 第三种方式是使用文件对象的 write() 方法,标准输出文件可以用 sys.stdout 引用。 如果你希望输出的形式更加多样,可以使用 str.format() 函数来格式化输出值。 如果你希望将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现。- str(): 函数返回一个用户易读的表达形式
- repr(): 产生一个解释器易读的表达形式 示例:
# 返回一个用户易读的表达形式x = str(1/7)print(x)# 产生一个解析器易读的表达形式y = 100 * 100print(repr(y))# 格式话print("{}网址:'{other}!'".format("百度",other="www.baidu.com")) 打印结果:
2). 读键盘输入
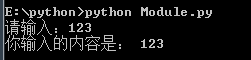
# 从键盘输入str = input("请输入:")print("你输入的内容是:", str) 打印结果:
3). 读写文件
- 读文件:open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
filename:filename 变量是一个包含了你要访问的文件名称的字符串值。
mode:mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。只读(r), 二进制读(rb),读写(r+),二进制读写(rb+),写(w),二进制写(wb),读写(w+),二进制读写(wb+),追加(a),二进制追加(ab),读写追加(a+),二进制读写追加(ab+).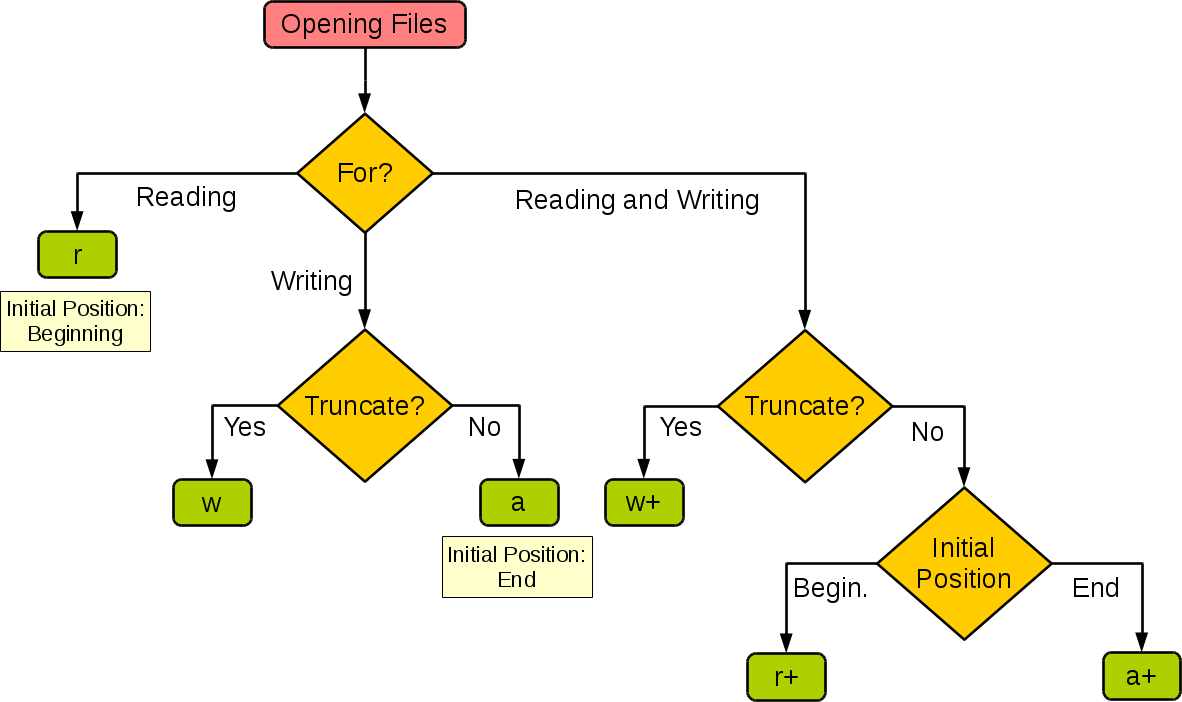
# 打开文件file = open("test.txt","w")# 定义数据str = "Python 是一个非常好的语言。"# 写入文件file.write(str)# 关闭打开的文件file.close 打印结果:
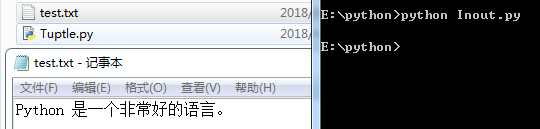
读取文件示例:
# 读取文件file = open("test.txt", "r")# 读取数据str = file.read()# 打印print(str)# 关闭打开文件file.close() 打印结果:

- readline(): 会从文件中读取单独的一行。换行符为 '\n'。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
- readlines(): 将返回该文件中包含的所有行。如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
- write(string):将 string 写入到文件中, 然后返回写入的字符数。
- tell():返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
- seek():如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符seek(x,1) : 表示从当前位置往后移动x个字符seek(-x,2):表示从文件的结尾往前移动x个字符from_what 值为默认为0,即文件开头。
- close(): 在文本文件中 (那些打开文件的模式下没有 b 的), 只会相对于文件起始位置进行定位。你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
4). pickle 模块
python的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储。通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。 基本接口:pickle.dump(obj, file, [,protocol])
有了 pickle 这个对象, 就能对 file 以读取的形式打开:
x = pickle.load(file)
注:从 file 中读取一个字符串,并将它重构为原来的python对象。
存入数据示例:# 导入pickleimport pickle# 使用pickle模块将数据对象保存到文件data = { 'a':[1,2.3,4,5+6j], 'b':('string', u'Unicode string'), 'c':None}# 打开文件output = open('data.pkl', 'wb')# 写入数据pickle.dump(data, output)# 关闭文件output.close() 写入数据示例:
# 导入pickleimport pprint,pickle# 使用pickle模块从文件中重构python对象file = open('data.pkl','rb')# 重构对象data = pickle.load(file)# 打印数据pprint.pprint(data)# 关闭文件file.close() 执行结果:

10. 遍历文件夹
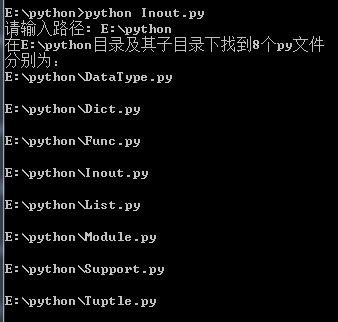
import osimport os.path# 获取指定目录及其子目录下的py文件l = []def get_py(path, list): # 获取path目录下的所有文件 fileList = os.listdir(path) for fileName in fileList: # 获取path与fileName组合后的路径 pathTmp = os.path.join(path, fileName) # 如果是目录 if os.path.isdir(pathTmp): # 递归查找 get_py(pathTmp, list) pass # 不是目录,则比较后缀名 elif fileName[-3:].upper()=='.PY': list.append(pathTmp) pass pass passpath = input("请输入路径: ").strip()get_py(path, l)print("在%s目录及其子目录下找到%d个py文件\n分别为:"%(path,len(l)))for filePath in l: print(filePath+'\n') pass 打印结果:
转载地址:http://pgnyl.baihongyu.com/